The Scanned PDF Converter That Actually Works
Precise recognition, preserved layouts — scanned docs become searchable, editable, and copyable
Drag & drop PDF file here
or
Supports PDF format, max 30 files, single file max 200MB, within 1500 pages


Conversion Examples
See the quality of our PDF conversions — preserving layouts, formulas, and formatting
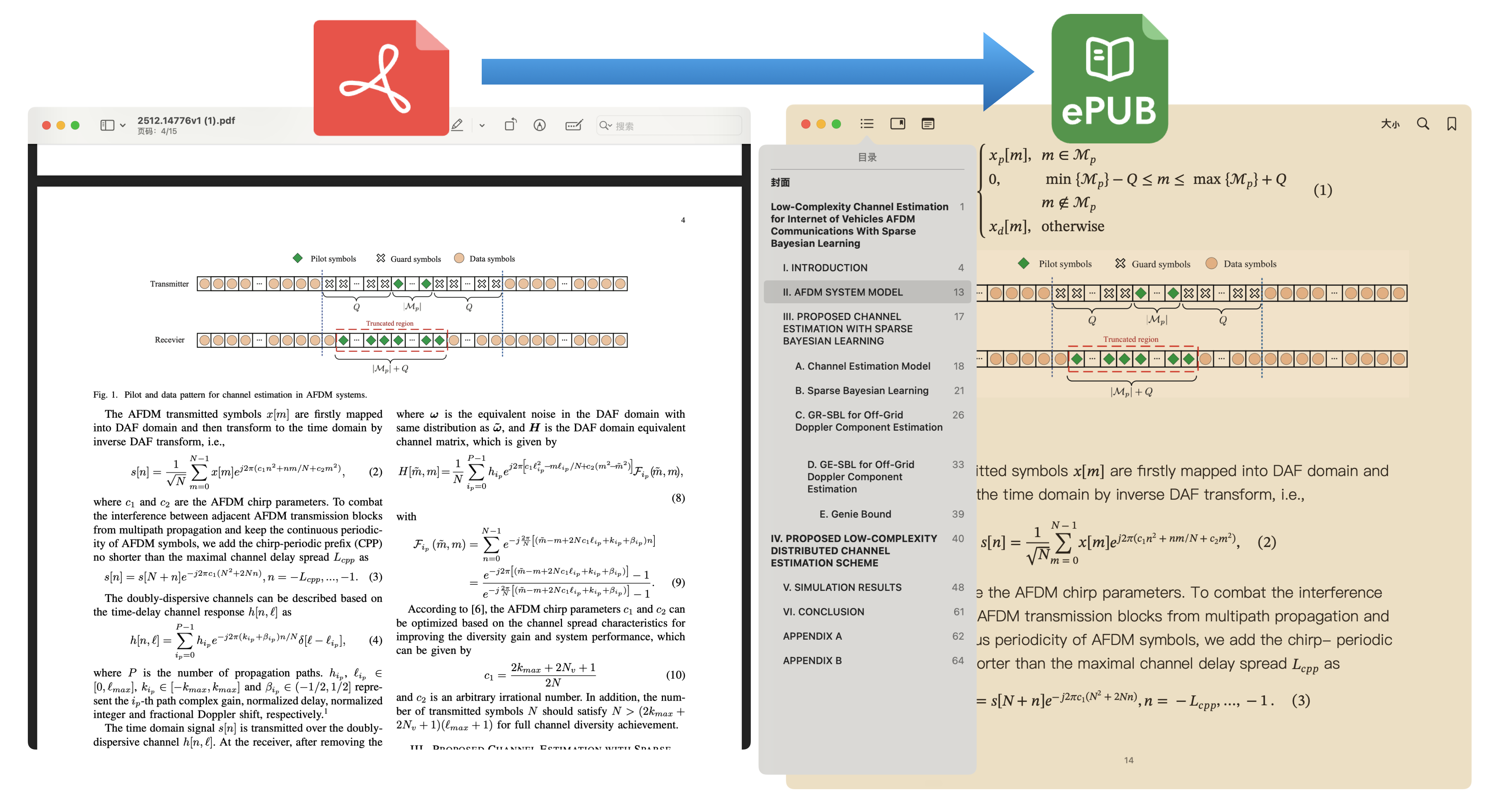
Perfect Math Formula Support
Accurately recognize mathematical formulas and chemical equations, supporting both inline and block formulas — ideal for academic documents
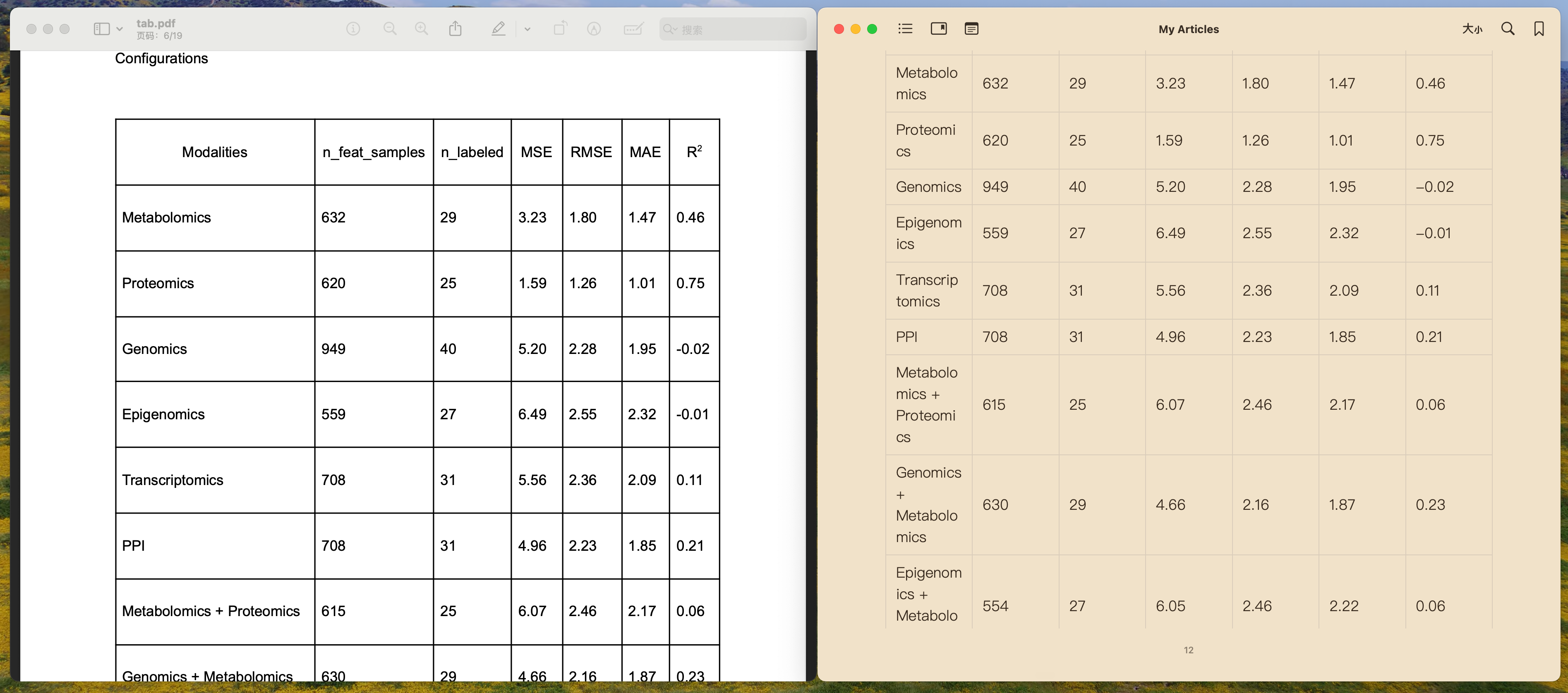
Structured Table Display
Intelligent recognition and preservation of table structures in PDFs, supporting accurate conversion and formatting of complex tables

PDF to EPUB
Convert complex PDF documents to beautifully formatted EPUB e-books with preserved structure

PDF to Markdown
Transform PDFs into clean Markdown with accurate formula recognition and layout preservation
Why Choose Inkora
Powerful OCR Recognition
Built on open-source DeepSeek-OCR, handles low-quality photos and scans
Accurate text recognition even from blurry scanned documents
Professional Layout Preservation
Smart detection of text-image layouts and two-column formats, ensuring continuous content
Maintains original book structure for a near-print reading experience
Perfect LaTeX Formula Support
Precise recognition of mathematical formulas and chemical equations, supporting inline and standalone display
The best choice for converting academic papers and textbooks
Rich Output Formats
Currently supports Markdown and EPUB formats, with more formats coming soon
Auto-generates table of contents and annotations for all e-readers
Open Source & API Support
MIT licensed with complete RESTful API for seamless integration
3000+ GitHub stars, perfect for enterprise batch processing and automation
100+ Languages Support
Support nearly 100 languages including Chinese, English, Japanese, Korean, Arabic, French, German, Spanish, and more
Automatic language detection and switching in multilingual mixed documents for high-precision recognition