真正能用的扫描版 PDF 转换工具
精准识别文字、公式、表格,完整保留原版排版,可搜可编可复制
拖放 PDF 文件到这里
或
支持 PDF 格式,最多 30 个文件,单文件最大 200MB,1500 页以内
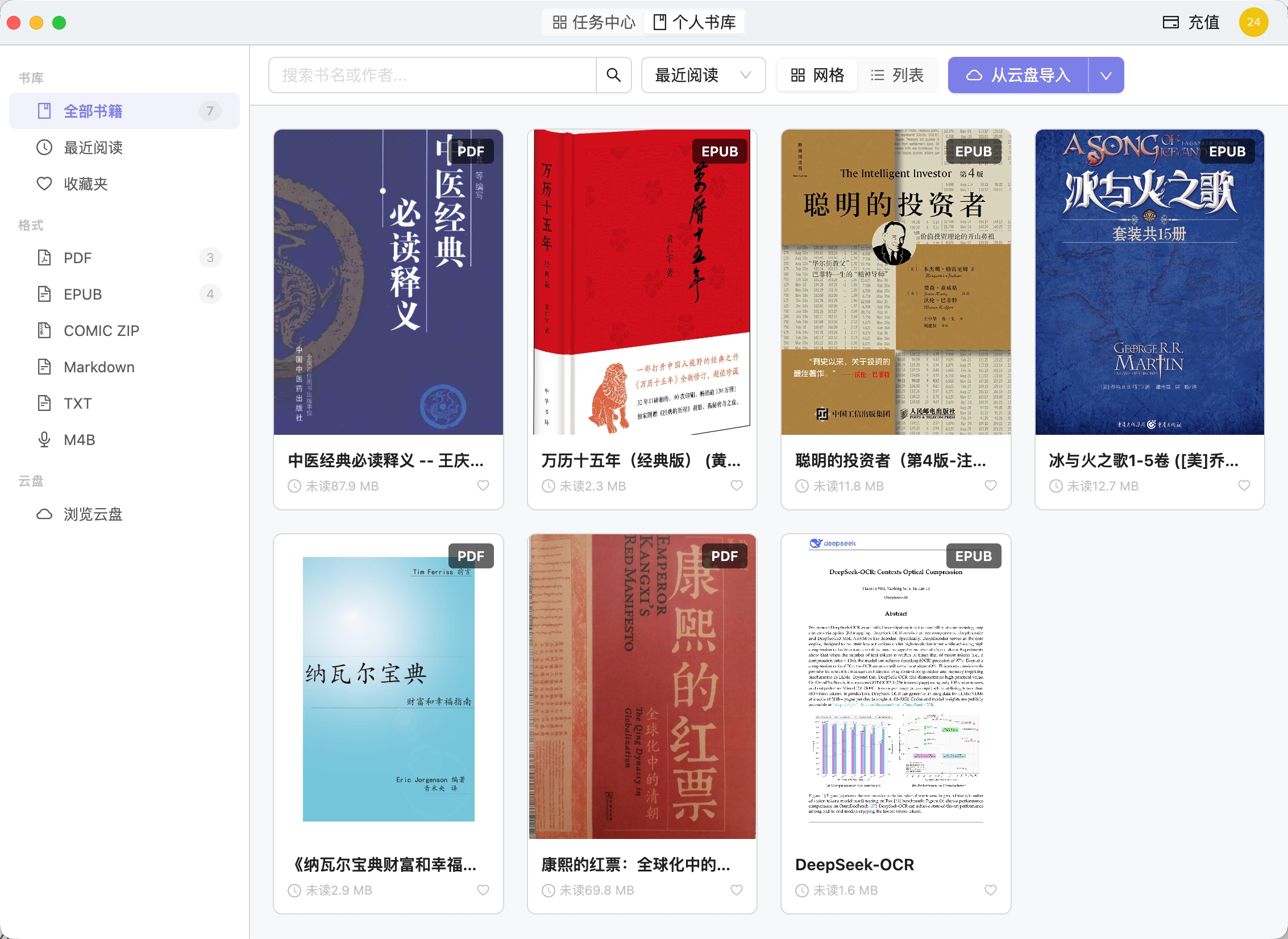


转换效果展示
查看我们的 PDF 转换质量 — 完美保留排版、公式和格式
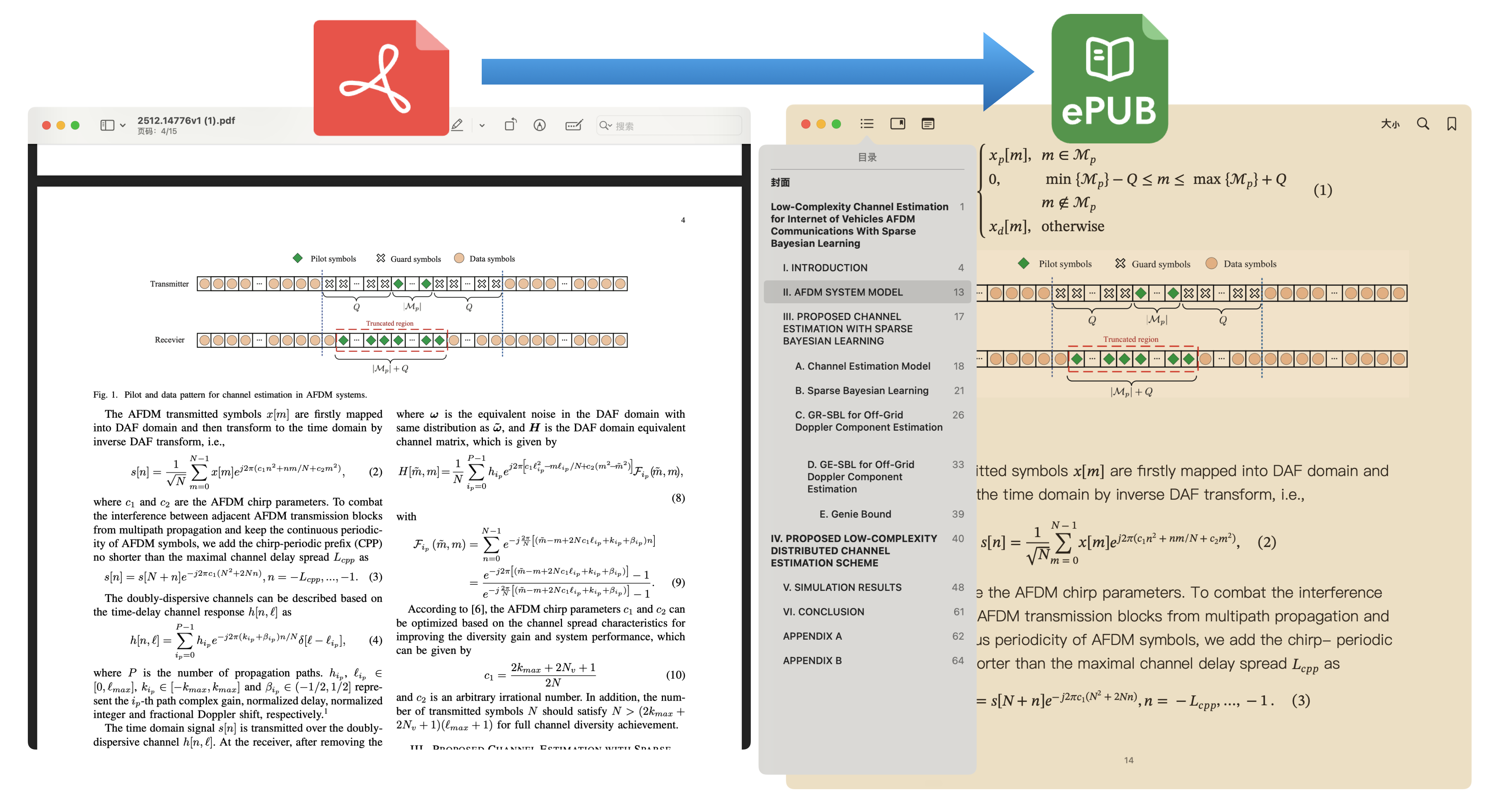
LaTeX
🔍
数学公式完美支持
精准识别数学公式、化学方程式,支持行内公式和独立公式,学术文档转换的最佳选择
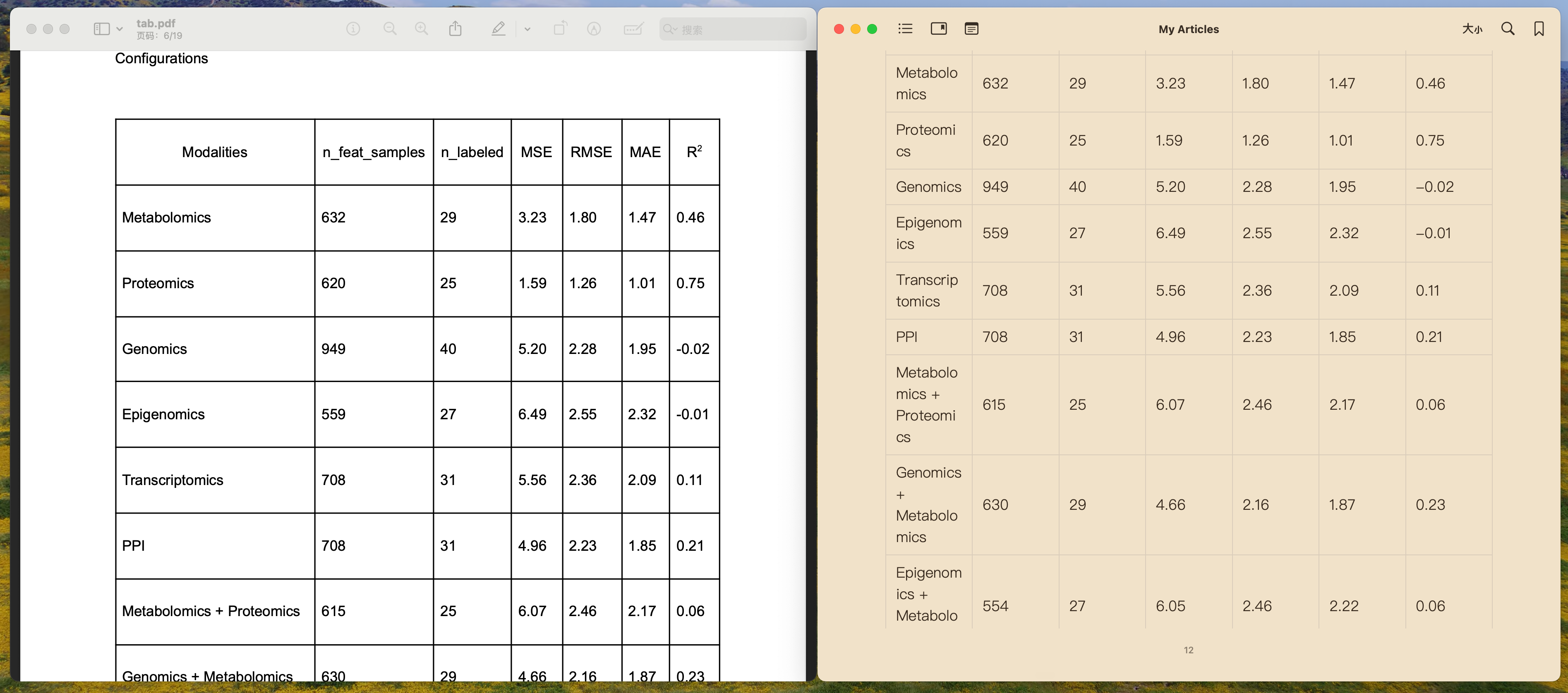
Table
🔍
表格结构化显示
智能识别并保留 PDF 中的表格结构,支持复杂表格的准确转换和格式化输出
EPUB

🔍
PDF 转 EPUB
将复杂的 PDF 文档转换为排版精美的 EPUB 电子书,完整保留原始结构
Markdown

🔍
PDF 转 Markdown
将 PDF 转换为整洁的 Markdown 格式,精准识别公式并保留排版布局
为什么选择 Inkora
🔍
强大的 OCR 识别能力
基于 DeepSeek-OCR 开源技术,支持拍照、扫描等低清晰度 PDF 识别
即使是模糊的扫描件,也能准确识别文字内容
📐
专业的排版还原
智能识别图文混排、双栏布局、表格排版,确保内容连续不截断
保留原书排版结构,阅读体验接近纸质书
∑
LaTeX 公式完美支持
精准识别数学公式、化学方程式,支持行内和独立公式显示
学术论文、教材转换的最佳选择
📚
丰富的输出格式
目前支持 Markdown 和 EPUB 格式,更多格式即将推出
自动生成目录、标注,满足各种阅读器需求
🔓
开源技术 & API 支持
MIT 协议开源,提供完整 RESTful API,轻松集成到您的应用
代码已在 GitHub 开源超过 3000+ star,适合企业级批量处理和自动化转换
🌍
100+ 语言支持
支持近100种语言,包括中文、英文、日文、韩文、阿拉伯文、法文、德文、西班牙文等
多语言混合文档自动检测切换,实现高精度识别